Correlation
The Conceptual Model
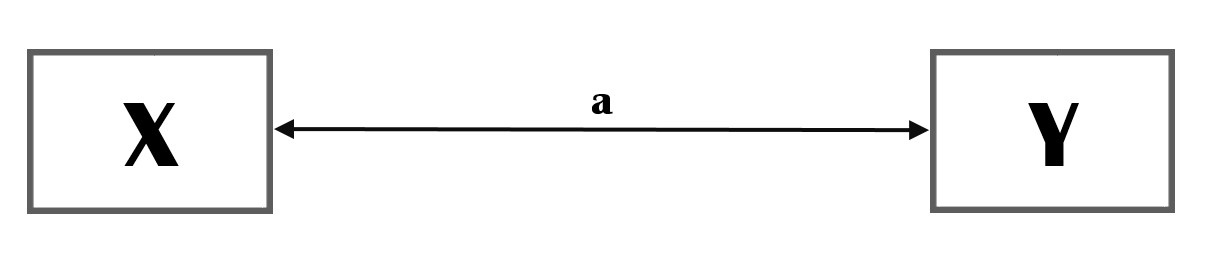
Figure 1: Correlation
Explanation
In a conceptual model, the concepts are normally placed in a rectangular. We have two concepts, X and Y.
The double headed arrow indicates that you do not assume a causal relation but a simple correlation. Thus: if X is high, Y is high; when Y is low, X is low.
It is not always necessary to label the paths but for this tutorial it will turn out to be handy. Normally, when there is no sign (or label) it is assumed that the path has a positive valence. It is, however, good practice to include the valence (+/-) of the paths in your conceptual models.
It is generally a good idea to use concepts that are (very) close to your actual measurements. Thus, although you may use the concept social cohesion in your conceptual model, this concept is overly broad and there is a fierce debate on how it should be defined theoretically and how we should measure it empirically. If you have measured social cohesion with for example a single item on generalized trust (“Generally speaking would you say that most people can be trusted or that you can’t be too careful in dealing with people?”) why not use the concept generalized trust in your conceptual model?
Abstract hypothesis
Hypo: X is related to Y.
or:
Hypo: X and Y are related
better:
Hypo: X and Y are positively related
Real life example
X is occupational success.
Y is health
Hypo 1a: People’s health and occupational success are positively related to each other.
You may have a more precise idea on why occupational success and health are related. Perhaps because of a third (unmeasured) concept such as social origin (e.g. income and parental education). That is, the relation is at least in part spurious (see menu on the left). Alternatively, you may assume two bidirectional causal mechanisms. In the latter case your hypothesis could read:
Hypo 1b: A higher occupational status will lead to a better health and a better health will lead to a higher occupational status.
Structural equations
- Y=X
or, following the syntax of the R package Lavaan
- Y~~X
The double ~~ indicates a (error)variance.
Formal test of hypotheses
Load the NELLS data.
rm(list = ls()) #empty environment
require(haven)
nells <- read_dta("../static/NELLS panel nl v1_2.dta") #change directory name to your working directoryOperationalize concepts.
# We will use the data of wave 2.
nellsw2 <- nells[nells$w2cpanel == 1, ]
# As an indicator of occupational success we will use income in wave 2.
table(nellsw2$w2fa61, useNA = "always")
attributes(nellsw2$w2fa61)
# recode (I will start newly created variables with cm from conceptual models)
nellsw2$cm_income <- nellsw2$w2fa61
nellsw2$cm_income[nellsw2$cm_income == 1] <- 100
nellsw2$cm_income[nellsw2$cm_income == 2] <- 225
nellsw2$cm_income[nellsw2$cm_income == 3] <- 400
nellsw2$cm_income[nellsw2$cm_income == 4] <- 750
nellsw2$cm_income[nellsw2$cm_income == 5] <- 1250
nellsw2$cm_income[nellsw2$cm_income == 6] <- 1750
nellsw2$cm_income[nellsw2$cm_income == 7] <- 2250
nellsw2$cm_income[nellsw2$cm_income == 8] <- 2750
nellsw2$cm_income[nellsw2$cm_income == 9] <- 3250
nellsw2$cm_income[nellsw2$cm_income == 10] <- 3750
nellsw2$cm_income[nellsw2$cm_income == 11] <- 4250
nellsw2$cm_income[nellsw2$cm_income == 12] <- 4750
nellsw2$cm_income[nellsw2$cm_income == 13] <- 5250
nellsw2$cm_income[nellsw2$cm_income == 14] <- 5750
nellsw2$cm_income[nellsw2$cm_income == 15] <- 6500
nellsw2$cm_income[nellsw2$cm_income == 16] <- 7500
nellsw2$cm_income[nellsw2$cm_income == 17] <- NA
# let us scale the variable a bit and translate into income per 1000euro
nellsw2$cm_income <- nellsw2$cm_income/1000
# from household income to personal income
attributes(nellsw2$w2fa62)
table(nellsw2$w2fa62, useNA = "always")
nellsw2$cm_income_per <- nellsw2$w2fa62
nellsw2$cm_income_per[nellsw2$cm_income_per == 1] <- 0
nellsw2$cm_income_per[nellsw2$cm_income_per == 2] <- 10
nellsw2$cm_income_per[nellsw2$cm_income_per == 3] <- 20
nellsw2$cm_income_per[nellsw2$cm_income_per == 4] <- 30
nellsw2$cm_income_per[nellsw2$cm_income_per == 5] <- 40
nellsw2$cm_income_per[nellsw2$cm_income_per == 6] <- 50
nellsw2$cm_income_per[nellsw2$cm_income_per == 7] <- 60
nellsw2$cm_income_per[nellsw2$cm_income_per == 8] <- 70
nellsw2$cm_income_per[nellsw2$cm_income_per == 9] <- 80
nellsw2$cm_income_per[nellsw2$cm_income_per == 10] <- 90
nellsw2$cm_income_per[nellsw2$cm_income_per == 11] <- 100
nellsw2$cm_income_per[nellsw2$cm_income_per == 12] <- NA
nellsw2$cm_income_ind <- nellsw2$cm_income * nellsw2$cm_income_per/100
# as an indicator of health we will use subjective well being from 5 (excellent) to 1 (bad) thus we
# have to reverse code original variable
attributes(nellsw2$w2scf1)
table(nellsw2$w2scf1, useNA = "always")
nellsw2$cm_health <- 6 - nellsw2$w2scf1##
## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 <NA>
## 55 78 103 204 338 326 282 272 276 205 133 62 48 22 22 29 374 0
## $label
## [1] " wat is het netto inkomen per maand van u en uw partner samen?/van u?/ "
##
## $format.stata
## [1] "%8.0g"
##
## $labels
## Minder dan ¤150 per maand ¤150 - ¤299 per maand ¤300 - ¤499 per maand
## 1 2 3
## ¤500 - ¤999 per maand ¤1.000 - ¤1.499 per maand ¤1.500 - ¤1.999 per maand
## 4 5 6
## ¤2.000 - ¤2.499 per maand ¤2.500 - ¤2.999 per maand ¤3.000 - ¤3.499 per maand
## 7 8 9
## ¤3.500 - ¤3.999 per maand ¤4.000 - ¤4.499 per maand ¤4.500 - ¤4.999 per maand
## 10 11 12
## ¤5.000 - ¤5.499 per maand ¤5.500 - ¤5.999 per maand ¤6.000 - ¤6.999 per maand
## 13 14 15
## ¤7.000 of meer per maand weet niet, wil niet zeggen
## 16 17
##
## $class
## [1] "haven_labelled" "vctrs_vctr" "double"
##
## $label
## [1] " hoe groot is uw bijdrage in dit inkomen ongeveer? kunt u een percentage noemen "
##
## $format.stata
## [1] "%8.0g"
##
## $labels
## vrijwel geen bijdrage ongeveer 10% ongeveer 20% ongeveer 30%
## 1 2 3 4
## ongeveer 40% ongeveer 50% ongeveer 60% ongeveer 70%
## 5 6 7 8
## ongeveer 80% ongeveer 90% ongeveer 100% weet niet
## 9 10 11 12
##
## $class
## [1] "haven_labelled" "vctrs_vctr" "double"
##
##
## 1 2 3 4 5 6 7 8 9 10 11 12 <NA>
## 253 48 89 259 233 242 183 229 114 63 887 229 0
## $label
## [1] " wat vindt u, over het algemeen genomen, van uw gezondheid? "
##
## $format.stata
## [1] "%8.0g"
##
## $labels
## uitstekend zeer goed goed matig slecht
## 1 2 3 4 5
##
## $class
## [1] "haven_labelled" "vctrs_vctr" "double"
##
##
## 1 2 3 4 5 <NA>
## 438 853 1211 247 48 32And test the correlation. Naturally, there are many ways to test for a correlation in R but in this tutorial I will try to do everything at least also in the package Lavaan.
But first plot the association:
# I randomly select 200 respondents otherwise the plot will be too crowded
selection <- sample(1:length(nellsw2$cm_income_ind), 200, replace = FALSE)
# because we are interested in a correlation, I plot the standardized variables
plot(scale(nellsw2$cm_income_ind[selection]), scale(nellsw2$cm_health[selection]), xlab = "income", ylab = "health",
main = "Association between income and health", sub = "(standardized variables)")
abline(lm(scale(nellsw2$cm_health) ~ scale(nellsw2$cm_income_ind), data = nellsw2), col = "red") I don’t see a very clear association. Perhaps at most a weak correlation.
I don’t see a very clear association. Perhaps at most a weak correlation.
And now,…the correlation
##
## Pearson's product-moment correlation
##
## data: nellsw2$cm_income_ind and nellsw2$cm_health
## t = 3.886, df = 2353, p-value = 0.0001047
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.03959172 0.11986098
## sample estimates:
## cor
## 0.0798558And with Lavaan.
require(lavaan)
model <- "
cm_income_ind ~~ cm_health
"
fit <- cfa(model, data = nellsw2) #I use cfa instead of lavaan. The only advantage is that I don't have to tell lavaan that I also need the variances of the variables.
summary(fit, standardized = TRUE)
# parameterEstimates(fit)## lavaan 0.6-7 ended normally after 10 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of free parameters 3
##
## Used Total
## Number of observations 2355 2829
##
## Model Test User Model:
##
## Test statistic 0.000
## Degrees of freedom 0
##
## Parameter Estimates:
##
## Standard errors Standard
## Information Expected
## Information saturated (h1) model Structured
##
## Covariances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## cm_income_ind ~~
## cm_health 0.074 0.019 3.863 0.000 0.074 0.080
##
## Variances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## cm_income_ind 1.023 0.030 34.315 0.000 1.023 1.000
## cm_health 0.839 0.024 34.315 0.000 0.839 1.000The covariance between the standardized variables is of course the correlation and this is the same value as the one obtained with cor.test().