Mediation
The Conceptual Model
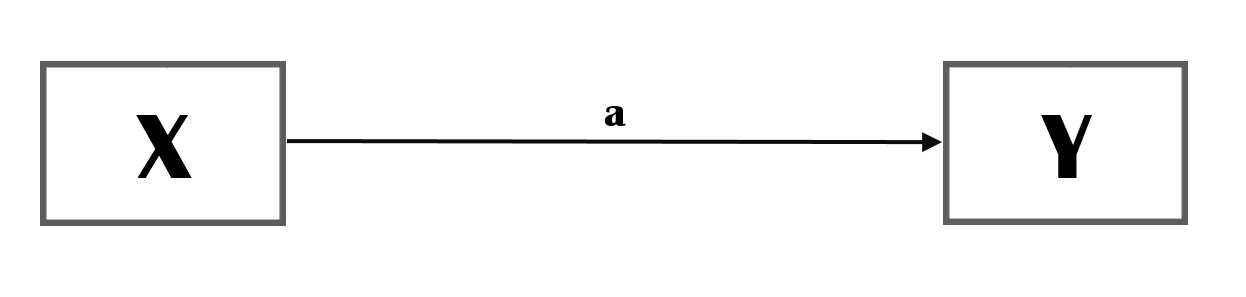
Figure 1: Total effect (a)
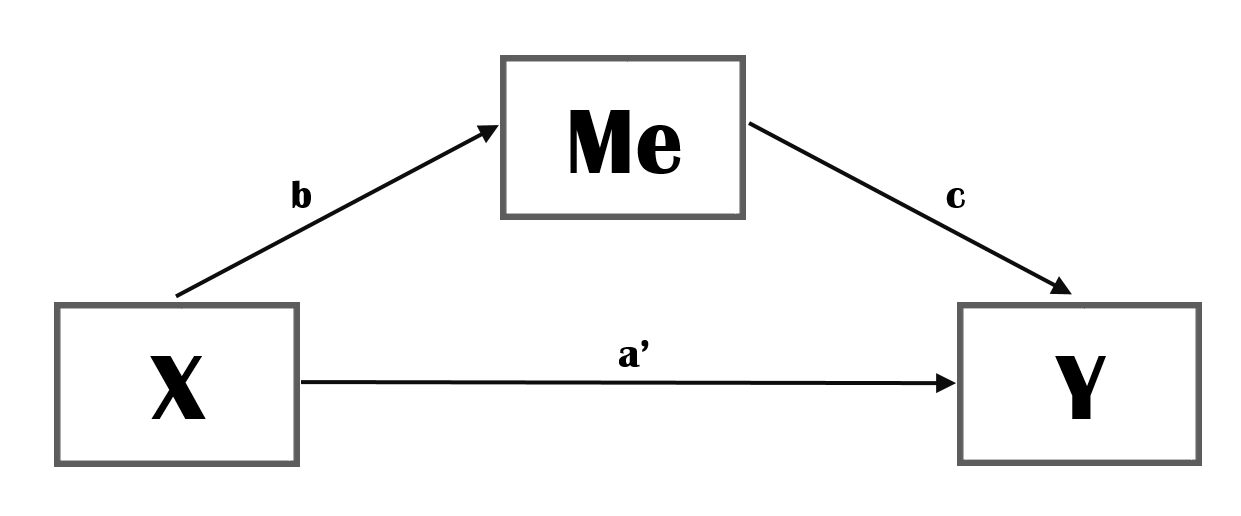
Figure 2: Mediation
Explanation
In a conceptual model, the concepts are normally placed in a rectangular. We have three concepts, X, the independent variable, Me, the mediator, and Y, the dependent variable.
We assume a causal relationship running from X to Y (See Figure 1).
We assume that in part this relationship can be explained by a Mediator, Me (See Figure 2). If you want to graphically depict a mediation mechanism, it may be useful to show the model without the mediator as well but this is a bit a matter of taste.
It is not always necessary to label the paths but for this tutorial it will turn out to be handy. Normally, when there is no sign (or label) it is assumed that the path has a positive valence. It is, however, good practice to include the valence of the paths in your conceptual models.
path names
- path a is called the total effect of X on Y.
- path a’ is called the direct effect of X on Y.
- the path running through the mediator, bc, is the indirect effect of X on Y.
Abstract hypothesis/hypotheses
Mediation
- Hypo1: X leads to Y (\(a>0\)).
- Hypo2: X leads to Me (\(b>0\)).
- Hypo3: Me leads to Y (\(c>0\)).
- Hypo4: Me mediates the relationship of X to Y (\(a' < a \equiv b*c>0\))
Please note, that:
- hypothesis 4 may hold even if hypothesis 2 and 3 are false.
- hypotheses 2, 3 and 4 may be true but that hypothesis 1 is false.
It is thus good practice to accept your mediation mechanism only if all four hypotheses hold true. Or more precisely, if you cannot refute any of the four hypotheses.
Suppression
Supression is closely related to mediation. It means that after taking into account Me the initial relations between X and Y becomes stronger.
This may occur when:
- \(a>0\) and (\(a' > a \equiv b*c<0\))
or:
- \(a<0\) and (\(a' < a \equiv b*c>0\))
Real life example
X is educational success
Me is occupational success.
Y is health
- Hypo1: Educational success leads to a better health.
- Hypo2: Educational success leads to occupational success.
- Hypo3: Occupational success leads to a better health.
- Hypo4: The relationship between educational success and health becomes weaker once we take into account that educational success causes occupational success and occupational success leads to a better health.
You will often encounter Hypo4s formulated as: The causal relation between educational success and health is (in part) explained by occupational success.
Structural equations
- Y=X
- Y=Me
- Me=X
or, following the syntax of the R package Lavaan
- Y~X + Me
- Me~X
Formal test of hypotheses
Load the NELLS data.
rm(list = ls()) #empty environment
require(haven)
nells <- read_dta("../static/NELLS panel nl v1_2.dta") #change directory name to your working directoryOperationalize concepts.
# We will use the data of wave 2.
nellsw2 <- nells[nells$w2cpanel == 1, ]
# As an indicator of occupational success we will use income in wave 2.
table(nellsw2$w2fa61, useNA = "always")
attributes(nellsw2$w2fa61)
# recode (I will start newly created variables with cm from conceptual models)
nellsw2$cm_income <- nellsw2$w2fa61
nellsw2$cm_income[nellsw2$cm_income == 1] <- 100
nellsw2$cm_income[nellsw2$cm_income == 2] <- 225
nellsw2$cm_income[nellsw2$cm_income == 3] <- 400
nellsw2$cm_income[nellsw2$cm_income == 4] <- 750
nellsw2$cm_income[nellsw2$cm_income == 5] <- 1250
nellsw2$cm_income[nellsw2$cm_income == 6] <- 1750
nellsw2$cm_income[nellsw2$cm_income == 7] <- 2250
nellsw2$cm_income[nellsw2$cm_income == 8] <- 2750
nellsw2$cm_income[nellsw2$cm_income == 9] <- 3250
nellsw2$cm_income[nellsw2$cm_income == 10] <- 3750
nellsw2$cm_income[nellsw2$cm_income == 11] <- 4250
nellsw2$cm_income[nellsw2$cm_income == 12] <- 4750
nellsw2$cm_income[nellsw2$cm_income == 13] <- 5250
nellsw2$cm_income[nellsw2$cm_income == 14] <- 5750
nellsw2$cm_income[nellsw2$cm_income == 15] <- 6500
nellsw2$cm_income[nellsw2$cm_income == 16] <- 7500
nellsw2$cm_income[nellsw2$cm_income == 17] <- NA
# let us scale the variable a bit and translate into income per 1000euro
nellsw2$cm_income <- nellsw2$cm_income/1000
# from household income to personal income
attributes(nellsw2$w2fa62)
table(nellsw2$w2fa62, useNA = "always")
nellsw2$cm_income_per <- nellsw2$w2fa62
nellsw2$cm_income_per[nellsw2$cm_income_per == 1] <- 0
nellsw2$cm_income_per[nellsw2$cm_income_per == 2] <- 10
nellsw2$cm_income_per[nellsw2$cm_income_per == 3] <- 20
nellsw2$cm_income_per[nellsw2$cm_income_per == 4] <- 30
nellsw2$cm_income_per[nellsw2$cm_income_per == 5] <- 40
nellsw2$cm_income_per[nellsw2$cm_income_per == 6] <- 50
nellsw2$cm_income_per[nellsw2$cm_income_per == 7] <- 60
nellsw2$cm_income_per[nellsw2$cm_income_per == 8] <- 70
nellsw2$cm_income_per[nellsw2$cm_income_per == 9] <- 80
nellsw2$cm_income_per[nellsw2$cm_income_per == 10] <- 90
nellsw2$cm_income_per[nellsw2$cm_income_per == 11] <- 100
nellsw2$cm_income_per[nellsw2$cm_income_per == 12] <- NA
nellsw2$cm_income_ind <- nellsw2$cm_income * nellsw2$cm_income_per/100
# as an indicator of educational success we will use highest completed level of education in years.
# the rationale behind this coding this I will take the maximum for university as 16.5 (taking into
# account that some masters are 2 years and some 1 year) and subsequently subtract the years needed
# to obtain a university degree given the degree under consideration.
attributes(nellsw2$w2fa102)
table(nellsw2$w2fa102, useNA = "always")
nellsw2$cm_education <- nellsw2$w2fa102
nellsw2$cm_education[nellsw2$w2fa102 == 1] <- 6
nellsw2$cm_education[nellsw2$w2fa102 == 2] <- 9
nellsw2$cm_education[nellsw2$w2fa102 == 3] <- 10
nellsw2$cm_education[nellsw2$w2fa102 == 4] <- 11
nellsw2$cm_education[nellsw2$w2fa102 == 5] <- 12
nellsw2$cm_education[nellsw2$w2fa102 == 6] <- 10
nellsw2$cm_education[nellsw2$w2fa102 == 7] <- 11
nellsw2$cm_education[nellsw2$w2fa102 == 8] <- 14
nellsw2$cm_education[nellsw2$w2fa102 == 9] <- 15
nellsw2$cm_education[nellsw2$w2fa102 == 10] <- 16.5
nellsw2$cm_education[nellsw2$w2fa102 == 11] <- 16.5
nellsw2$cm_education[nellsw2$w2fa102 == 12] <- 7
nellsw2$cm_education[nellsw2$w2fa102 == 13] <- 11
nellsw2$cm_education[nellsw2$w2fa102 == 14] <- 14.5
nellsw2$cm_education[nellsw2$w2fa102 == 15] <- 4
# as an indicator of health we will use subjective well being from 5 (excellent) to 1 (bad) thus we
# have to reverse code original variable
attributes(nellsw2$w2scf1)
table(nellsw2$w2scf1, useNA = "always")
nellsw2$cm_health <- 6 - nellsw2$w2scf1##
## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 <NA>
## 55 78 103 204 338 326 282 272 276 205 133 62 48 22 22 29 374 0
## $label
## [1] " wat is het netto inkomen per maand van u en uw partner samen?/van u?/ "
##
## $format.stata
## [1] "%8.0g"
##
## $labels
## Minder dan ¤150 per maand ¤150 - ¤299 per maand ¤300 - ¤499 per maand
## 1 2 3
## ¤500 - ¤999 per maand ¤1.000 - ¤1.499 per maand ¤1.500 - ¤1.999 per maand
## 4 5 6
## ¤2.000 - ¤2.499 per maand ¤2.500 - ¤2.999 per maand ¤3.000 - ¤3.499 per maand
## 7 8 9
## ¤3.500 - ¤3.999 per maand ¤4.000 - ¤4.499 per maand ¤4.500 - ¤4.999 per maand
## 10 11 12
## ¤5.000 - ¤5.499 per maand ¤5.500 - ¤5.999 per maand ¤6.000 - ¤6.999 per maand
## 13 14 15
## ¤7.000 of meer per maand weet niet, wil niet zeggen
## 16 17
##
## $class
## [1] "haven_labelled" "vctrs_vctr" "double"
##
## $label
## [1] " hoe groot is uw bijdrage in dit inkomen ongeveer? kunt u een percentage noemen "
##
## $format.stata
## [1] "%8.0g"
##
## $labels
## vrijwel geen bijdrage ongeveer 10% ongeveer 20% ongeveer 30%
## 1 2 3 4
## ongeveer 40% ongeveer 50% ongeveer 60% ongeveer 70%
## 5 6 7 8
## ongeveer 80% ongeveer 90% ongeveer 100% weet niet
## 9 10 11 12
##
## $class
## [1] "haven_labelled" "vctrs_vctr" "double"
##
##
## 1 2 3 4 5 6 7 8 9 10 11 12 <NA>
## 253 48 89 259 233 242 183 229 114 63 887 229 0
## $label
## [1] " wat is uw hoogst voltooide opleiding, dat wil zeggen waarvan u een diploma heef"
##
## $format.stata
## [1] "%8.0g"
##
## $labels
## lagere school
## 1
## lbo, vmbo-kb\\bbl
## 2
## mavo, vmbo-tl
## 3
## havo
## 4
## vwo\\gymnasium
## 5
## mbo-kort (kmbo), primair leerlingwezen, bol\\bbl niveau 1 of
## 6
## mbo-tussen\\lang (mbo), secundair\\tertiar leerlingwezen, bol\\
## 7
## hbo
## 8
## universiteit (bachelor)
## 9
## universiteit (master, doctoraal)
## 10
## promotietraject
## 11
## buitenlandse opleiding, niet goed in te delen, lager onderwi
## 12
## buitenlandse opleiding, niet goed in te delen, middelbaar on
## 13
## buitenlandse opleiding, niet goed in te delen, hoger onderwi
## 14
## geen opleiding
## 15
##
## $class
## [1] "haven_labelled" "vctrs_vctr" "double"
##
##
## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <NA>
## 118 223 202 205 117 223 737 586 89 208 12 8 20 17 34 30
## $label
## [1] " wat vindt u, over het algemeen genomen, van uw gezondheid? "
##
## $format.stata
## [1] "%8.0g"
##
## $labels
## uitstekend zeer goed goed matig slecht
## 1 2 3 4 5
##
## $class
## [1] "haven_labelled" "vctrs_vctr" "double"
##
##
## 1 2 3 4 5 <NA>
## 438 853 1211 247 48 32And test the model with Lavaan.
require(lavaan)
var(nellsw2$cm_income_ind, na.rm = TRUE)
model <- "
# direct effect
cm_health ~ a*cm_education
# mediator
cm_income_ind ~ b*cm_education
cm_health ~ c*cm_income_ind
# indirect effect
bc := b*c
# total effect
total := a + (b*c)
"
fit <- sem(model, data = nellsw2)
summary(fit, standardized = TRUE)
inspect(fit, "r2") #to obtain r-squared## [1] 1.021848
## lavaan 0.6-7 ended normally after 12 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of free parameters 5
##
## Used Total
## Number of observations 2326 2829
##
## Model Test User Model:
##
## Test statistic 0.000
## Degrees of freedom 0
##
## Parameter Estimates:
##
## Standard errors Standard
## Information Expected
## Information saturated (h1) model Structured
##
## Regressions:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## cm_health ~
## cm_educatn (a) 0.055 0.008 7.044 0.000 0.055 0.154
## cm_income_ind ~
## cm_educatn (b) 0.137 0.008 17.972 0.000 0.137 0.349
## cm_health ~
## cm_incm_nd (c) 0.019 0.020 0.959 0.338 0.019 0.021
##
## Variances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .cm_health 0.815 0.024 34.103 0.000 0.815 0.974
## .cm_income_ind 0.887 0.026 34.103 0.000 0.887 0.878
##
## Defined Parameters:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## bc 0.003 0.003 0.957 0.338 0.003 0.007
## total 0.058 0.007 7.873 0.000 0.058 0.161
##
## cm_health cm_income_ind
## 0.026 0.122We need to refute our mediation mechanism. Do you see why?
Well, because income is not related to SWB, at least not when we take into account educational success. Our c-path is not significant.
Thus, the reason why we observed a positive relation between income and SWB previously was because of omitted variable bias.